
前言
为什么要本地部署大模型(如 GPT 等 AI 模型),相对于云端服务有哪些明显的优点简要说明下:
1. 数据隐私和安全性
本地部署可以确保敏感数据不会离开内部网络,从而减少数据泄露的风险。这在涉及敏感信息(如金融、医疗或个人隐私数据)的场景中尤其重要。
2. 低延迟和高性能
对于实时应用或需要快速响应的场景,本地部署能够减少网络延迟,因为模型和数据都在本地运行。
3. 控制成本
虽然云端提供按需付费的模型服务,但当推理请求量非常大时,成本可能会迅速增加。本地部署虽然初期硬件成本较高,但在长期使用中可能比按使用量付费的云服务更具经济性。
4. 离线能力
在无法访问互联网或网络连接不稳定的环境下,云服务不可用时,本地部署依然可以工作
5.合规及审查要求
在金融、医疗和政府部门等领域,通常有严格的合规要求,禁止或限制将数据传输至第三方云服务。在这种情况下,本地部署成为唯一的选择。此外,本地部署的模型可以使用未经审查的版本,提供了更高的开放性和自由度。
本地安装运行大模型运行环境框架 Ollama 统一管理大模型
目前个人体验中,最简单的本地部署大模型的方式是使用ollama(https://ollama.com/),尤其适合拥有至少 16G 显存的 NVIDIA 显卡的环境。以下是其部署步骤概览:
1,安装 Ollama:
- 访问 Ollama 官网 并下载适用于 macOS 或 Windows 的安装包。
- 按照提示安装 Ollama。安装过程中会配置必要的依赖项和环境。
2,下载模型:
- 打开终端(或命令行界面),运行以下命令来下载所需的大语言模型:
ollama pull llama2 - 你可以根据需要选择不同的模型版本,例如
llama2或其他可用模型。
3,运行模型:
- 下载完成后,使用以下命令启动模型:
ollama run llama2 - 系统将启动模型,并提供一个本地服务供你进行交互。
与模型交互:
- 模型启动后,你可以通过命令行直接输入问题,或将其与本地应用集成,通过 API 调用来生成文本。
其实ollama应该是一个对docker的封装,熟悉docker命令的应该不难上手。比如
ollama list 列出所有的模型
ollama rm <模型名> 删除模型。
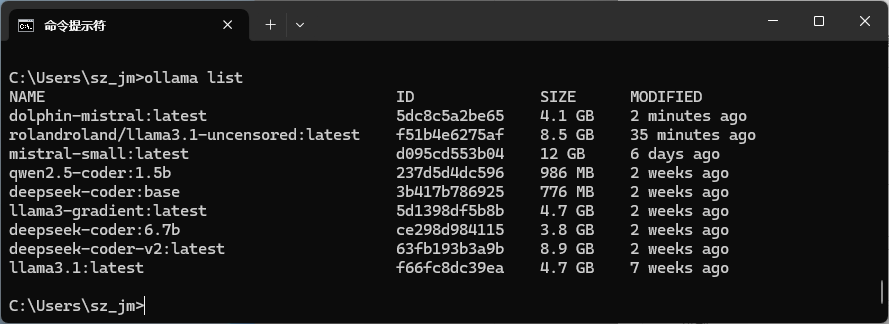
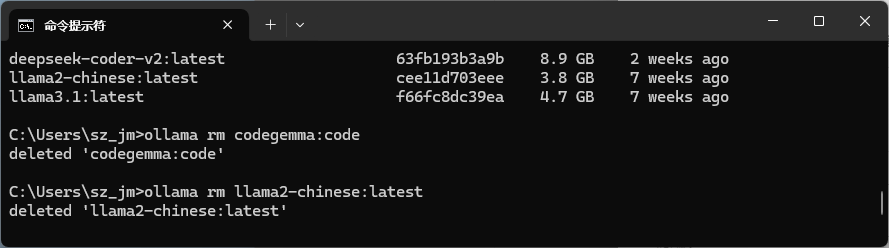
在此基础上,模型已经可以在本地运行了。不过,使用命令行交互可能不太方便,因此推荐一个用户界面友好的开源项目 ChatBox 来调用本地模型。
使用 ChatBox 与本地模型交互的步骤
在 ChatBox 中,你可以输入问题,模型会根据输入进行响应。ChatBox 提供了直观的界面和交互体验,适合日常使用和测试。
1.下载并安装 ChatBox:
访问 ChatBox 官网,下载适用于 macOS、Windows 或 Linux 的安装包。
完成安装后,启动 ChatBox 应用。
2.配置 ChatBox 连接本地模型:
在 ChatBox 的设置界面中,找到“模型设置”。
输入 Ollama 提供的本地 API 地址,例如 http://localhost:port(端口号请参阅 Ollama 的输出信息)。
保存设置,ChatBox 会自动连接到本地的 Ollama 模型。
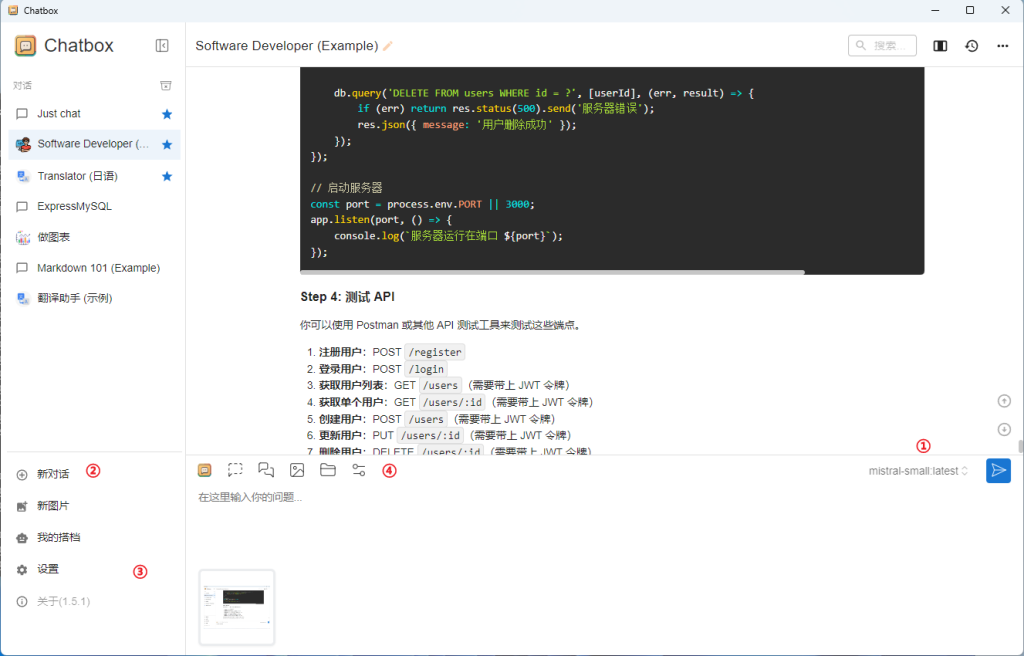
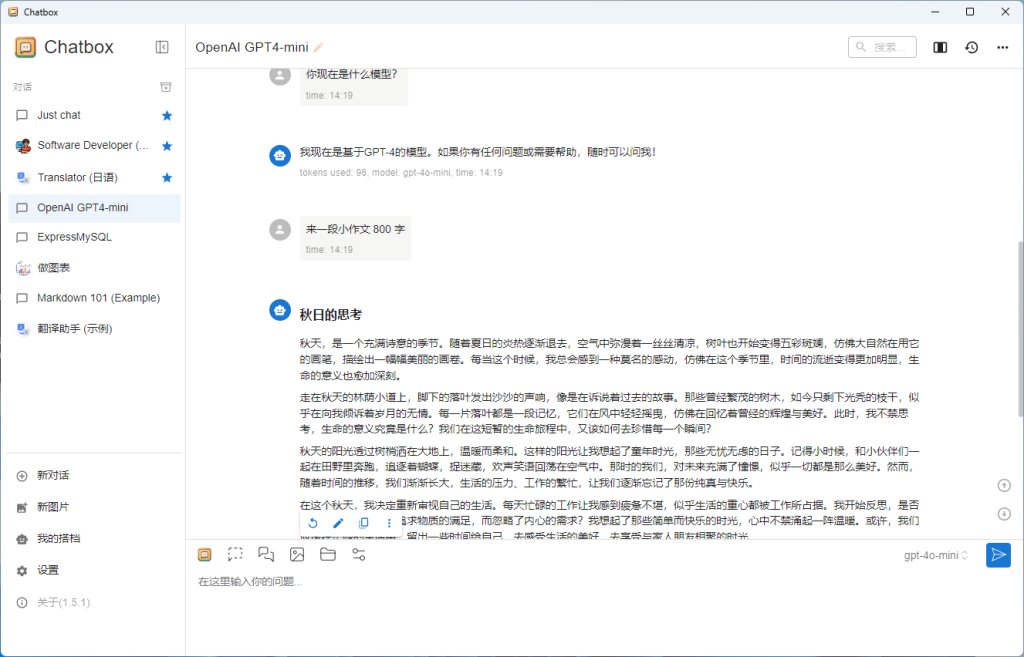
①切换模型 ②开始新会话 ③全体的配置(比如链接设置等)
④当前会话的设置(比如更改初始的提示词,模型等)
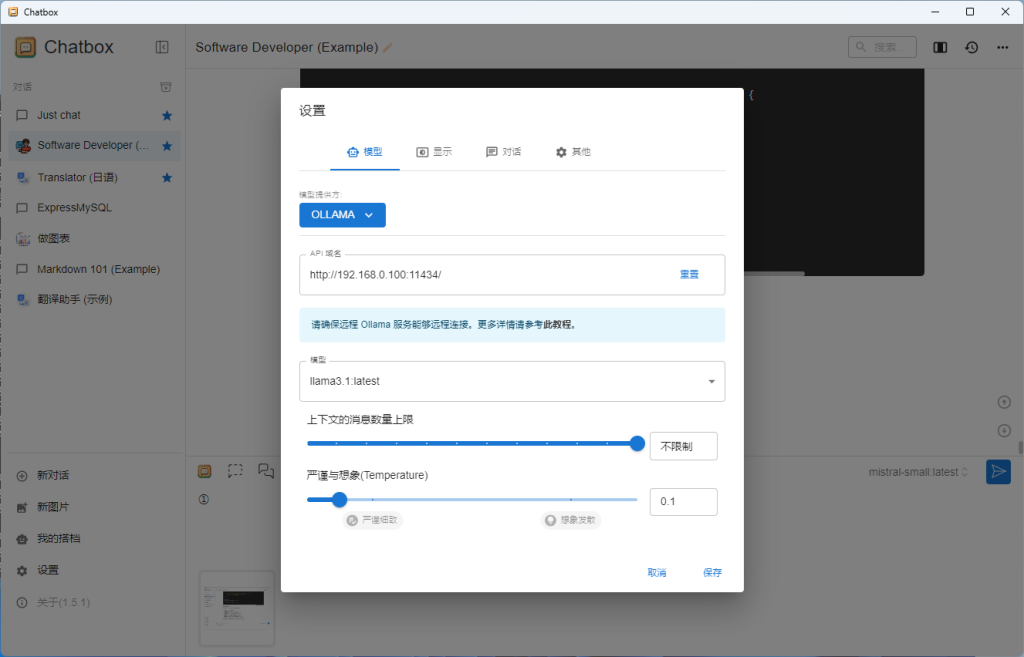
上图是设置画面,ChatBox不仅支持ollama,还支持市面上主流的在线大语言模型,比如openAI GoogleGemini等等,通过追加配置,可以很方便的在多个语言模型(本地,远程,各个模型)中切换
到这里,我们已经有了目前所有的武器,当然作为程序员,我们还希望在开发环境里面集成使用本地模型
MSCode的CodeGPT插件介绍
我们这里只介绍配置使用ollama本地模型的方法,本身CodeGPT 这个插件希望你注册用户,并且付费经由他来使用大模型,但是我们完全可以在不注册的情况下使用本地模型。(20241025目前的情况)
安装插件:
- 在 VSCode 的扩展市场中搜索
CodeGPT,找到插件并点击 Install 安装。 - 安装完成后,插件图标会出现在 VSCode 的左侧活动栏中。
使用插件:
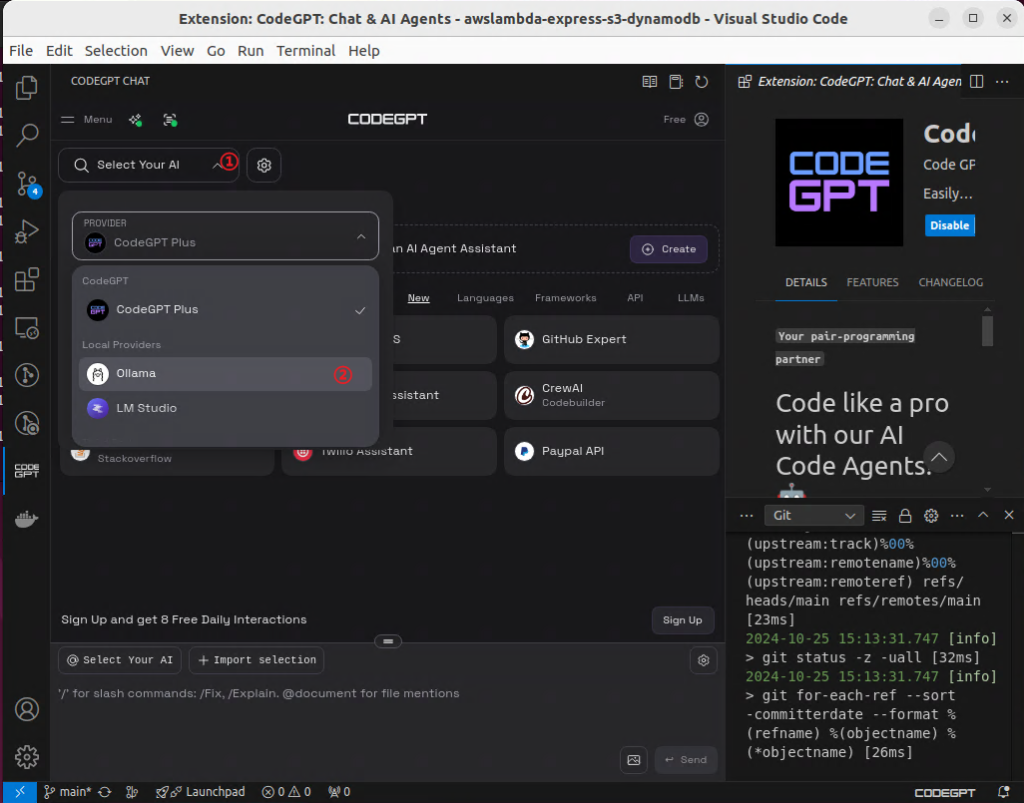
①「CodeGPTPlus」是CodeGPT提供的,不注册没法使用,我们需要在这里选择② Ollama 本地模型
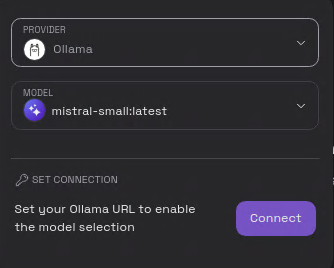
这里点击【Connect】输入Ollama的地址,!不支持非localhost,似乎集成了管理的功能,不过这个不能阻止我们,使用比如gost这个小工具或者iptable端口转发一下,就能指向局域网的ollama的API接口。
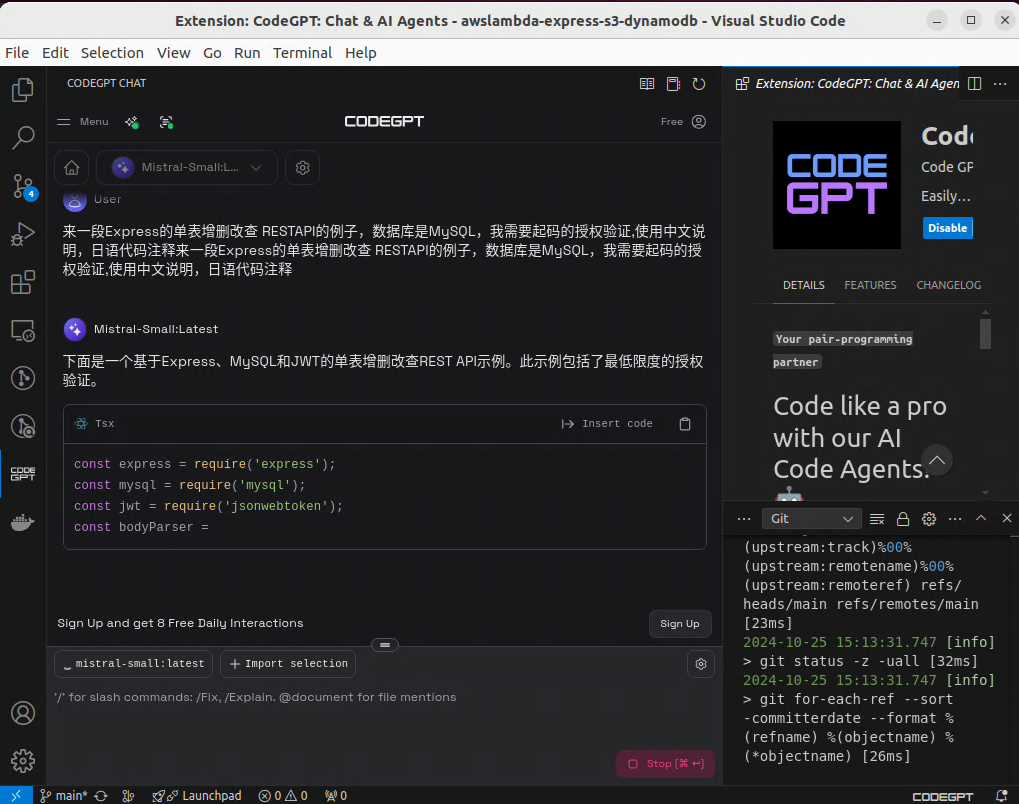
这样我们就能使用Chat功能了,这里我们需要注意的是 Chat的模型和自动补全(Autocomplete)的模型是不一样的,我们需要在这里设置
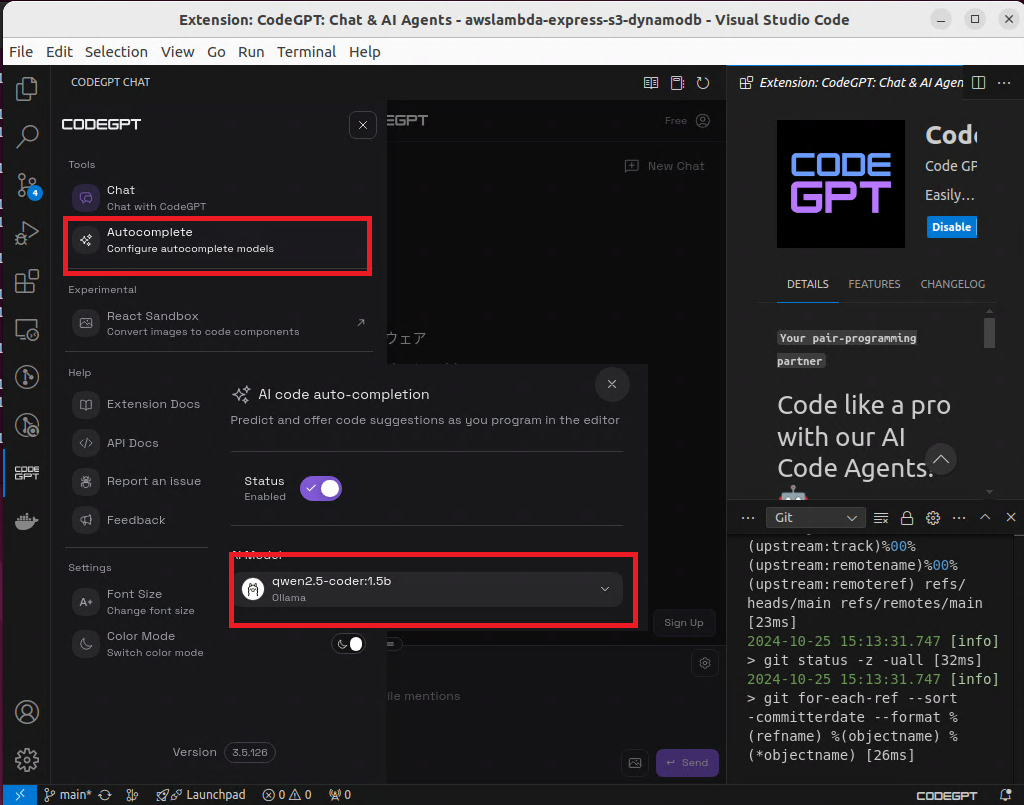
这里开启

①自动补全开关 ②Tab 功能开关
最后:
最终,通过这些操作,我们基本上打造了一个类似Cursor的智能开发环境,完全不依赖互联网且免费。然而,受限于本地模型的运行需求,由于我的显卡只有16G显存,运行更大的模型会显得捉襟见肘,效能受到一定限制。此外,因本地部署的模型是自行安装的,可能需要在不同模型间进行效果对比,以找到最符合需求的方案。